Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, Geoffrey J. Gordon
논문 review에 앞서 Catastrophic forgetting이란, 이미 어떤 dataset에 대해서 학습이 완료된 network에 또 다른 dataset(task)를 학습시키면 이전의 information들을 잊어버리는 현상을 말한다.
일반적인 classification 문제는 위와같이 R을 minimize하는 방향으로 SGD optimization을 통해 학습을 한다.
Time step t+1에서의 acc < t에서의 acc: forgetting event가 발생한것.

논문 review에 앞서 Catastrophic forgetting이란, 이미 어떤 dataset에 대해서 학습이 완료된 network에 또 다른 dataset(task)를 학습시키면 이전의 information들을 잊어버리는 현상을 말한다.
Abstract
catastrophic forgetting에 영감을 받아서, single classification tasks에서도 비슷한 현상(learning dynamics)이 일어나는 것을 본 논문에서 다루고자 한다. Forgetting event를 "training시에, 이전에 맞췄던 sample에 대해서 못맞추는 현상"이라고 정의할 때, 아래와 같은 중요한 사실을 발견했다.
1. 어떠한 example들은 높은 주기로 forgotten되고, 어떤 example들은 아예 forgotten되지 않는다.
2. 어떤 dataset의 (un)forgettable example들은 neural architecture에 관계없이 일반화 될 수 있다.
3. 따라서, 상당수의 training examples들이 생략되어져도 generalized된 SOTA performance를 보였다.
Introduction
본 논문은 single classifictaion task의 SGD optimization에서 mini batch에 대해서 time T에서는 정답으로 예측하였으나, time T'(T' > T) 에서는 틀려버린 경우에 대해서 분석하고자 한다. 이를 위해 첫번째, 계속해서 forgotten 되거나 unforgotten되는 example이 존재하는 지에 대해서 찾아 본후, Forgettable/unforgettable example가 model의 decision에 어떤 영향을 끼치는지, 그리고 generalization error에는 어떤 영향을 끼치는 지에 대해서 분석하였다.
본 논문의 목적은 크게 2가지이다.
1. Compressibility of the dataset: data efficiency는 높이면서 generalization accuracy는 유지를 하고싶다.
2. Forgetting statistics를 이용하여 중요한 example, outlier example, noisy label을 가지는 example들을 알아내보고 싶다.
실험적으로 다음과 같은 발견을 하였다고 한다.
1. 무수히 많은 Unforgettable example들이 존재하며, seed 혹은 network architecture에 따라서 Unforgettable example들이 달라지지 않았다.
2. noisy label을 가지는 example들과 uncommon한 feature를 가지는 image들은 대부분 forgotten examples에 속했다.
3. 대부분의 UnForgotten examples를 제거하고 학습시켜도 test accuracy를 유지할 수 있었다.
Defining and Computing Example Forgetting
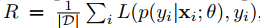 |
| L는 Cross Entropy를, p는 Network Parameter를 이용하여 input xi가 주어졌을때 yi가 나올 확률이다. |
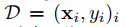 |
| Obeservation/label pair |
Forgetting and learning events
 |
| SGD time step t가 지났을 때 top-1으로 예측된 label |
 |
| Binary 변수: time step t가 지났을 때 top-1으로 예측된 label이 정답이라면 1, 아니라면 0. |
Time step t+1에서의 acc < t에서의 acc: forgetting event가 발생한것.
Time step t+1에서의 acc > t에서의 acc: learning event.
Classification margin
 |
| input에 대해 모델이 내놓은 logit값을 sigmoid(softmax)를 거치게함. |
 |
| k: 정답 클래스의 index. 즉, m은 정답 클래스에 대한 logit 값과 정답 클래스가 아닌 다른 클래스중 가장 높은 logit값을 가지는 값의 차이 |
Unforgettable examples
Unforgettable example이란 어떤 time step t*에서 learned 되었었고(acc=1) k>= t에 대해서 k step에 대한 acc값이 계속해서 1인 경우를 뜻한다.
따라서 계속해서 acc=0이었던 example은 위 정의에 맞지 않으며, 한번이라도 k step에서 acc이 0이 되버리면 forgettable example로 정의한다.
Procedural description and experimental setting
training sample각각에 대해서 만약 현재 mini batch에 포함되어있으면 forgetting event가 발생하였는지에 대한 count값을 계속해서 tracking함. 그 후, dataset의 모든 example에 대해서 count값을 가지고 sorting을 진행. learnt 되지 않은 sample들은 count값을 무한대로 주었다고 한다.
-> computationally expensive하므로 cheaper한 방법을 뒤에서 소개한다.
 |
| <Forgetting count를 계산하는 알고리즘> |
Characterizing example forgetting
Number of forgetting events:
모델 weight값에 대한 seed값을 다르게 주면서(5번), Forgetting events count값에 대한 histogram을 아래와 같이 나타냈다.
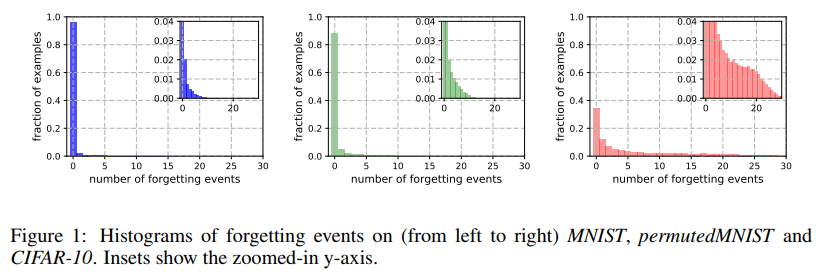 |
MNIST의 경우 91%정도가 unforgettable training examples로 구성되어있다. permuted MNIST-> CIFAR10로 갈 수록 unforgettable training example 개수가 줄어드는데, 이는 forgetting statistics가 complexity of dataset과 관련이 있을 수도 있다는 사실을 보여준다.
First learning events
처음으로 Learnt되는 시점에 대해서 unforgettable example과 forgettable example이 다를 것인가를 조사를 해보았더니, forgettable과 unforgettable set에서 많은 example들이 3~4번의 step에서 learnt 되었지만 forgettable set같은 경우 훨씬 더 많은 수의 example들이 training 후기에 처음으로 learnt되었다고 한다.
Visual inspection

top: 쉽게 인식할 수 있고 obvious하다.
bottom: 애매한 부분을 가지고 있고, 같은 class의 다른 data들 보다 uncommon한 feature를 가지고 있다.
Detection of noisy examples
" Most forgettable한 example들은 전형적이지 않은 uncommon한 특징을 가지고 있다. "
를 증명하는 부분. 이게 만약 맞다면, noisily-labeled examples(총 examples 중 20% 정도를 label을 임의로 바꿔준 examples)들은 forgetting event count값이 높을 것이라는 가정을 하였다.
아래의 결과는 왼쪽의 경우 noisy example과 original example간의 forgetting event 발생 횟수 비교를 나타내고 오른쪽의 경우 같은 example들인데 label noise를 적용하기 전/ 후를 나타낸 것이다. 왼쪽에서, noisy example들 같은 경우 unforgettable example이 존재하지 않는다.


background color 는 training 되고 있는 partition을 나타낸다. (a)의 경우 random하게 partition을 쪼갠 경우이고, (b)의 경우 unforettable examples와 non-zero forgetting examples로 쪼갠 경우이다. a.2과 b.2에서보면, 실제로 partition 2(forgotten at least once)에 대해서 학습을 시작하자마자, partition 1(never forgotten)에대한 forgetting이 시작되는 것을 볼 수 있다. b.3과 c.2에서 보면, forgotten 되지 않는 examples들은 training partition이 바뀌어도 forgetting이 mild하게 되는 것을 볼 수 있다. 이는 forgotten at least once example들이 never forgotten을 support해준다는 것을 나타낸다.
 왼쪽 그림의 경우 forgetting event count를 ascending order로 지워봤을 때의 결과이다.
왼쪽 그림의 경우 forgetting event count를 ascending order로 지워봤을 때의 결과이다.
(각 포인트는 small subset of training data를 가지고 scratch로부터 retraining한 것이다.) 검은색 선은 모든 unforgotten example들이 지워진 시점이다. 이 시점부터 forgotten data들이 지워지게 되면서 성능드랍이 되기 시작한다.
Random하게 지웠을 때는 성능 드랍이 굉장히 빠르게 이뤄진다.
오른쪽 그림의 경우 5000개의 training examples를 forgetting event count에 대해 ascending order로 지워본 결과이다. 각 점은 5000개를 제외하고 학습시킨 결과를 나타내며 가로축은 5000개에 대해서 average forgetting count를 나타낸 것이다. 그래프에서 볼 수 있듯, avg forgetting count가 커질수록 성능 드랍이 심해진다. 특이한점은 오른쪽 끝에서보면 다시 성능이 올라가는데, 이는 Visual Inspection에서 언급했던 성능에 악영향을 주는 Forgettable examples(uncommon한 feature를 가지는) 들이 지워졌으므로 성능이 올라간 것이라고 해석하고 있다.
처음으로 Learnt되는 시점에 대해서 unforgettable example과 forgettable example이 다를 것인가를 조사를 해보았더니, forgettable과 unforgettable set에서 많은 example들이 3~4번의 step에서 learnt 되었지만 forgettable set같은 경우 훨씬 더 많은 수의 example들이 training 후기에 처음으로 learnt되었다고 한다.
Visual inspection
top: 쉽게 인식할 수 있고 obvious하다.
bottom: 애매한 부분을 가지고 있고, 같은 class의 다른 data들 보다 uncommon한 feature를 가지고 있다.
Detection of noisy examples
" Most forgettable한 example들은 전형적이지 않은 uncommon한 특징을 가지고 있다. "
를 증명하는 부분. 이게 만약 맞다면, noisily-labeled examples(총 examples 중 20% 정도를 label을 임의로 바꿔준 examples)들은 forgetting event count값이 높을 것이라는 가정을 하였다.
아래의 결과는 왼쪽의 경우 noisy example과 original example간의 forgetting event 발생 횟수 비교를 나타내고 오른쪽의 경우 같은 example들인데 label noise를 적용하기 전/ 후를 나타낸 것이다. 왼쪽에서, noisy example들 같은 경우 unforgettable example이 존재하지 않는다.
Continual Learning Setup
CIFAR10과 같은 상대적으로 어려운 데이터셋에서는 많은 example들이 forgotten되는 현상을 보였다. 이는 하나의 classification task 에서도 catastrophic forgetting이 일어날 수 있다라고 볼 수 있기에, CIFAR10 training set에서 10K개의 examples를 샘플링한 후, 이를 두개의 partition(각각 5K개)으로 쪼개서 altenatively 학습을 진행했다고 한다. 각각 20 epochs씩 학습을 진행했으며, 각 partition에 대한 validation accuracy를 기록하였다(실선 - 5개 학습시킨 성능 average값).background color 는 training 되고 있는 partition을 나타낸다. (a)의 경우 random하게 partition을 쪼갠 경우이고, (b)의 경우 unforettable examples와 non-zero forgetting examples로 쪼갠 경우이다. a.2과 b.2에서보면, 실제로 partition 2(forgotten at least once)에 대해서 학습을 시작하자마자, partition 1(never forgotten)에대한 forgetting이 시작되는 것을 볼 수 있다. b.3과 c.2에서 보면, forgotten 되지 않는 examples들은 training partition이 바뀌어도 forgetting이 mild하게 되는 것을 볼 수 있다. 이는 forgotten at least once example들이 never forgotten을 support해준다는 것을 나타낸다.
Removing Unforgettable Examples
한번 forgotten 된 examples는 unforgettable examples에 영향을 준다는 사실에서 봤을 때, unforgettable examples는 학습에 있어서 informative하지 않다는 사실을 내포한다. 따라서 training시에 forgotten되는 examples는 학습에 있어서 useful하다. 아래의 그림은 Training dataset으로 부터 subset of examples를 지워봤을 때의 CIFAR 10에서의 결과이다.
(각 포인트는 small subset of training data를 가지고 scratch로부터 retraining한 것이다.) 검은색 선은 모든 unforgotten example들이 지워진 시점이다. 이 시점부터 forgotten data들이 지워지게 되면서 성능드랍이 되기 시작한다.
Random하게 지웠을 때는 성능 드랍이 굉장히 빠르게 이뤄진다.
오른쪽 그림의 경우 5000개의 training examples를 forgetting event count에 대해 ascending order로 지워본 결과이다. 각 점은 5000개를 제외하고 학습시킨 결과를 나타내며 가로축은 5000개에 대해서 average forgetting count를 나타낸 것이다. 그래프에서 볼 수 있듯, avg forgetting count가 커질수록 성능 드랍이 심해진다. 특이한점은 오른쪽 끝에서보면 다시 성능이 올라가는데, 이는 Visual Inspection에서 언급했던 성능에 악영향을 주는 Forgettable examples(uncommon한 feature를 가지는) 들이 지워졌으므로 성능이 올라간 것이라고 해석하고 있다.
Transferable Forgetting Events
ResNet18 모델에 대해서 Ordering(Forgetting event statistics)을 얻은 후 이를 통해 Data의 일부를 increasing order로 지워보면서 WideResNet에 대해서 실험을 진행했을 때, 30%가 지워져도 성능을 유지하였다. 이를 통해 Big architecture에 대한 training time을 줄일 수 있다는게 이 논문의 주장이다.
본 논문의 의의 및 향후 연구 방향:
Future work involves understanding forgetting events better from a theoretical perspective, exploring potential applications to other areas of supervised learning, such as speech or text and to reinforcement learning where forgetting is prevalent due to the continual shift of the underlying distribution.
댓글
댓글 쓰기