Abstract
이전의 CNN based SR 모델들은 LR image로 부터 나오는 Hierarchical features를 충분히 이용하지 않았다. 이에 따라 성능이 낮았다.
본 논문에서는 Residual Dense Network(RDN)를 통해 이 문제를 해결하고자 한다. RDN은 모든 convolutional layer로 부터 나오는 hierarchical feature를 아래와 같이 충분히 이용한다.
1. Residual Dense Block(RDB)를 사용하여 Dense connected convolutional layer로 부터 나오는 local feature를 추출하고자 한다.
2. RDB는 이전의 RDB output이 현재 RDB의 모든 layer의 input으로 들어가게 설계 하였다.
3. Local Feature Fusion을 통해 이전의 RDB output과 local features를 충분히 이용하여 학습할 수 있도록 하였다.
4. 위와 같은 dense local features를 학습 한 후에, Global feature fusion을 통해 global hierarchical feature를 학습하게 된다.
Introduction
Network의 뒷단에 갈 수록 각각의 convolutional layer는 계층적으로 다른 receptive field를 갖게 된다. SRCNN, VDSR, DRCN과 같은 기존의 SR Methods는 각각의 convolutional layer의 receptive field를 충분히 이용하지 않았다.
매우 깊은 네트워크에서의 Hierarchical feature는 reconstruction할 때 유용한 정보를 많이 줄 수 있으나, 기존 SR methods는 이를 충분히 이용하지 않았다.
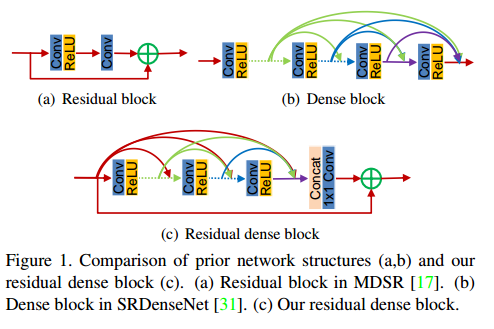
이러한 결점을 해결하기 위하여, RDN을 제안한다. 이를 통해 input으로부터 나온 hierarchical features를 아래의 그림 (c) RDB를 통해 충분히 이용하고자 한다.
RDN의 모델 구조는 아래의 그림과 같다.

그림 1.(c)와 같이 RDB는 dense connected layers로 구성되어있고 local feature fusion(LFF)를 통해 local residual learning을 하고 있다.
또한 아래의 그림에서 볼 수 있듯이 이전의 RDB block이 차후 RDB block의 모든 layer의 input으로 연결되어 있다. 이를 통해 보존되어야 하는 정보들을 전달할 수 있다.
따라서, 그림 1.(c)에서 볼 수 있듯이 LFF는 정보를 보존시키면서 local dense feature를 추출할 수 있게 된다.

그림 3에서, 이렇게 여러개의 RDB block에서 local dense feature를 뽑아낸 후에, 그림 2처럼 global feature fusion(GFF)를 통해 global하게 hierarchical feature들을 보존시킨다.
본 논문의 의의는 다음과 같이 3가지로 정리될 수 있다.
1. Original LR image로 부터 나오는 hierarchical feature들을 충분히 이용할 수 있는 High-quality image SR method: RDN.
2. RDB 에서는 local dense feature를 뽑고, local feature fusion을 통해 보존되어야 하는 정보들을 보존할 수 있게 된다.
3. GFF를 통해서 global hierarchical features를 합칠 수 있다. 또한 Global residual learning을 통해서 low-level feature와 high-level feature를 합칠 수 있어서 original LR image로 부터 나온 global dense features를 뽑아낼 수 있다.
Residual Dense Network for Image SR
Network Structure
그림 2 에서 볼 수 있듯이, 4개의 부분으로 나뉠 수 있다: Shallow feature extraction net(SFENet), Residual Dense Blocks(RDBs), Dense Feature Fusion(DFF), up-sampling net (UPNet). I LR을 RDN의 input, I SR을 RDN의 output이라고 표기해보면, 첫번째 Conv layer는 다음과 같은 수식으로 나타낼 수 있다.

H SFE1 는 첫번째 shallow feature extraction layer 를 나타낸다.
첫번째 Conv layer의 output으로 나온 F-1는 Global residual connection으로 사용된다.
두번째 Conv layer는 다음과 같은 수식으로 나타낼 수 있다.

H SFE2 는 두번째 shallow feature extraction layer를 나타낸다.
F0는 첫번째 RDB의 input으로 사용된다.
d번째 RDB에 의해서 나온 output을 Fd라고 하면 다음과 같은 수식으로 나타낼 수 있다.

H RDB,d는 d번째 RDB 를 의미한다.
이 때 Fd는 block 내의 각 convolutional layer를 충분히 이용하여 생성된 feature map이므로 local dense feature라고 한다.
이렇게 여러개의 RDB를 거쳐서 hierarchical feature를 추출해낸 다음, Dense Feature Fusion(DFF)를 하게된다. DFF는 두가지 과정 Global Feature Fusion(GFF)와 Global Residual Learning(GRL)을 수반한다. 이렇게하여 DFF는 모든 layer로부터 나온 features를 완전히 이용할 수 있고 이는 다음과 같이 수식으로 나타낼 수 있다.

F DF는 DFF의 결과로 나오는 output feature map이다.
LR space에서 Local, Global feature를 뽑아낸 다음, Upsampling Net(UPNet)을 통해 HR space로 바꿔주는데, 이 때 ESPCN의 Efficient sub-pixel convolutional layer를 사용한다. 이를 통해 최종 output I SR이 아래와 같이 나오게 된다.

Residual Dense Block
그림 3에서보면, RDB는 3가지 부분으로 나뉠 수 있다. Dense connected layers, local feature fusion(LFF), local residual learning(LRL), Contiguous Memory(CM) mechanism.
먼저 Contiguous Memory mechanism이란 이전의 RDB output을 현재 RDB의 모든 layer의 input으로 connection을 주는 것을 의미한다.
F d-1을 d번째 RDB의 input, F d를 output이라고 하고 이 둘의 channel 수는 G0로 동일하다고 가정하자. 그러면 d번째 RDB 내의 c번째 Conv layer의 output 은 다음과 같이 정의 된다.

여기서 σ는 ReLU를 나타내고 W d,c는 c번째 Conv layer의 weights를 나타낸다. []는 channel wise concatenation을 나타낸다. 즉, 이전의 RDB 의 output과 현재 RDB 내의 c 번째 이전 conv layers의 output들을 concat한다음, Convolution 시키고 ReLU를 통과시켜 c번째 Conv layer의 output을 얻게 된다. 이는 feed-forward 이면서도 local dense feature를 뽑아내주는 효과를 보인다
Local Feature Fusion이란 그 RDB 내에서 모든 Conv layer의 output feature map과 이전 RDB의 output을 concat한다음 1x1 Convolution으로 채널 수를 줄여주는 것을 말한다. 이는 다음과 같이 수식으로 나타낼 수 있다.

여기서 H d LFF는 d번째 RDB에서의 1x1 Convolution을 나타낸다.
Local Residual Learning이란 local feature fusion의 output과 이전 RDB의 output을 합치는 것이다. 이는 Network representation ability를 높여서 성능을 더 좋게 한다.
Dense Feature Fusion
여러 개의 RDB를 거쳐 local dense features를 얻은 후에, Dense Feature fusion(DFF)을 통해 hierarchical features를 global하게 이용하려고 한다. DFF는 Global Feature Fusion(GFF)와 Global residual learning으로 이루어져 있다.
Global Feature Fusion이란 각 RDB로부터 나온 output feature maps를 concat 한다음 1x1 convolution, 3x3 convolution을 거치도록 하여 Global Feature를 뽑는 것이다.
Global residual learning이란 Global Feature Fusion으로 부터 나온 Global Feature와 Network의 첫번째 Conv layer의 output F-1를 add 해주는 것을 말한다.
여기서, Global residual learning은 long term connection인데, MemNet같은 경우도 long term connection을 사용하였지만 local feature information이 dense하게 connected되어있지 않기 때문에 long term connection을 제한한다.
Implementation Details
- 모든 Conv layers filter size : 3 x 3, padded zero to keep size fixed, output channel수: G
- 모든 RDB의 output channel 수: 64
- Upscale을 위해서, Efficient sub-pixel convolutional layer 사용
- 최종 output channel 수: 3
Discussions
Differences to DenseNet
1. DenseNet은 object recognition에 많이 쓰이는 반면, RDN은 image SR에 쓰인다.
2. BN(Batch Normalization)을 없앴다 -> Convolutional layer와 연산량이 비슷해서 연산량을 증가시키고 성능을 악화시켰다.
3. Pooling layer를 없앴다. -> 중요한 pixel 정보를 버릴 수 있기 때문
4. Local Feature Fusion(LFF)의 존재 -> (d-1) block이 d block에 connect되고 결과적으로 (d+1) block에도 영향을 줌.
5. Global Feature Fusion(GFF)의 존재 -> global hierarchical feature를 완전히 이용함.
질문: BN이 왜 성능을 악화시키는지?
Differences to SRDenseNet
1.CM Mechanism의 존재: 이전의 RDB를 현재 RDB에 connection을 맺어주도록 함. 또한 RDB 내에서 Local Residual Learning을 사용해서 information과 gradient가 잘 흐를 수 있도록 함.
2. RDB 사이의 dense connection이 없음: 그 대신, Global Feature Fusion(GFF)와 global residual learning을 통해 global feature를 추출해내 도록함.
3. SRDenseNet은 L2 loss를 사용하지만 RDN은 L1 loss를 사용 -> 수렴이 빠르고 성능이 더 좋다.
L1 loss가 outlier에 대해서 더 robust하기 때문. (L2는 outlier가 있으면 그거에 대해서 minimize하기 위해서 왜곡되게됨)
Difference to MemNet
1. MemNet은 LR image를 bicubic interpolation을 통해 HR image로 만들어준 다음 이를 input으로 하여 HR space에서 feature extraction 및 reconstruction하므로 연산량이 많다. 반면에 RDN은 original LR image가 input으로 들어가고 hierarchical feature를 사용하므로 성능도 좋고 연산량도 많이 줄었다.
2. MemNet에서는 memory block에서 recursive & gate unit을 사용한다. 이는 이전의 layer로부터 아무런 정보를 받지 않는다. 그러나 RDN에서는 RDB의 output이 다음 RDB의 모든 layer에 connected되어 있어서 정보를 전달해주고, RDB 안에서도 이전의 layer가 다음 layer에게 정보를 전달해주므로 information flow가 잘 흐르게 되있다.
3. Fully exploitating hierarchical features: GFF를 통해서 hierarchical features를 fuse함.
Experimental Results
Settings
- Training Dataset:
DIV2K Resolution dataset(800 training images, 100 validation images, 100 test images) 실험에서는 Validation time때 5개의 이미지를 사용하였음.
- Test Dataset:
Set5, Set14, B100, Urban100.
- Degradation Models:
1. BI: Input HR image를 Bicubic Interpolation을 통해 resize함(scale factor of x2, x3, x4).
2. BD: Input HR image를 7x7 Gaussian kernel (with std 1.6) 를 통해 blur하게 만들고 scale factor x3 으로 downsample함
3. DN: Input HR image를 scale factor x3 으로 downsample 후에 Gaussian noise를 noise level 30으로 줌. Most Challenging한 case임.
- Training setting:
* Training batch 내에서 32 x 32 size로 LR image를 random crop함.
* Data augmentation by Flipping horizontally or Vertically and rotating.
* Adam optimizer를 사용, Learning rate 는 10 -4승, 200 epoch 마다 절반으로 줄어들게끔 하였음.
* 200 epochs를 돌리는데 Titan Xp에서 1일 정도 걸렸다고 한다.
Study of D,C, and G
D: RDB의 개수
C: RDB당 Conv layer의 개수
G: Growth rate

(a), (b)에서 볼 수 있듯이, D값이 크면 성능이 더 좋아지고, C값을 크게하면 성능이 좋아지는 것을 확인할 수 있다. 이에 대해서는 논문에서 "Network가 깊어지기 때문에" 라고 설명하고 있다.
또한 LFF에서 1x1 convolution으로 local dense feature maps의 channel수(G)를 조절 할 수 있기 때문에 G값을 크게 줬더니 성능이 더 높아지는 것을 (c)에서 확인할 수 있다.
Ablation Investigation

위 그림은 CM(Continuous Memory), LRL(Local Residual Learning), GFF(Global Feature Fusion)에 대한 Ablation study 결과를 나타낸 것이다. 이 실험에서 D = 20, C = 6, G = 32로 주었고, LFF는 모든 케이스에 대해서 적용시켰다.
CM, LRL, GFF를 다 적용하지 않은 케이스를 보면, 성능이 매우 낮은 것을 볼 수 있는데 이는 단순히 DenseNet처럼 Dense block을 쌓는다고 해서 더 좋은 성능을 내지 못한다는 것을 보여준다.
CM, LRL, GFF 중 하나를 적용한 케이스들을 보면, 모두다 적용하지 않은 케이스 보다 성능이 훨씬 좋아진 것을 볼 수 있다. 이는 CM, LRL, GFF 각각이 Information flow와 gradient flow를 더 풍부하게 제공해줄 수 있게 도와주기 때문이다.
CM, LRL, GFF 중 두개를 적용한 케이스들을 보면, 한개만 적용한 케이스들에 비하여 성능이 조금 더 좋아진 것을 볼 수 있다.
CM, LRL, GFF 셋 다 적용한 케이스가 모든 케이스들에 대해서 성능이 최고로 좋다.
모든 케이스에 대해서 학습 Convergence graph는 다음과 같이 나왔다고 한다. (Set5, scale factor x2 사용)

RDN_CM1LRL1GFF0 는 "CM는 적용, LRL는 적용, GFF는 미적용 케이스" 를 나타낸다.
위 그래프를 통해 CM, LRL, GFF 각각은 training process를 stabilize해주고 성능을 높여준다는 것을 확인 할 수 있다.
Results with BI Degradation Model
SR분야에서 흔히 쓰이는 BI degradation model을 다른 methods와 비교한 결과는 아래와 같다.

* RDN+는 RDN Ensemble 모델을 의미한다.
다른 methods에서 Conv layer마다 보통 64개의 필터를 사용하므로 G값을 64로 주었다고 한다. 그러나 EDSR같은 경우 256개 필터를 사용하므로 훨씬 wider한 Network이므로 비교 대상에서 제외시켰으나 RDN은 EDSR에 비해 비슷하거나 더 좋은 결과를 보였다고 한다.
위 표에서 볼 수 있듯, RDN은 MemNet과 SRDenseNet에 비해서 훨씬 더 좋은 성능을 보였다. 이로써, MemNet의 Memory block과 SRDensenet의 Dense block보다는 Residual Dense Block이 더 좋다는 것을 입증했다.
그러나, MDSR에 비교했을 때는 x3, x4 에 대해서는 성능이 거의 비슷한 것을 볼 수 있는데 이는 두 가지 이유 때문이라고 논문에서 주장한다.
1. MDSR은 RDN보다 Network Depth가 깊어서 LR space에서 feature를 더 잘 뽑을 수 있어! (MDSR: 160 개 Conv layer, RDN: D x C = 128 개 Conv layer)
2. MDSR은 multi-scale input을 이용하였음.
3. MDSR은 더 큰 input patch size를 사용하여 학습하였음! (MDSR: 65 x 65, RDN: 32 x 32) 따라서 "더 많은 정보를 얻을 수 있기 때문에 성능이 더 올라간 것임!"
아래의 사진은 scale factor x4에 대해서 Visually 다른 methods와 비교한 결과이다.

첫번째 사진에서 보면 다른 모델은 blurry한 부분과 artifacts들을 생성한 것을 볼 수 있지만 RDN은 엣지부분이 깔끔하고 좀 더 예리하게 복원된 것을 볼 수 있다.
두번째 사진에서, 다른 모든 모델은 선(빨간색 화살표로 표시된 부분)을 나타내는 데 실패 했지만 RDN은 선을 명확하게 나타내는 데 성공했다. 이는 Dense feature fusion을 통해 Hierarchical features를 잘 이용했기 때문이라고 자랑하고 있다.
Results with BD and DN Degradation Models
아래의 표는 Set5, Set14, B100, Urban100, Manga109에 대해서 scale factor x3를 적용시켜 다른 methods와 비교한 표이다. RDN ensemble 이 모든 dataset에 대해서 성능이 제일 좋다.

아래의 그림은 BD degradation model에 대해서 Visually 다른 methods와 비교한 결과이다.

RDN을 제외한 다른 methods들은 LR image를 HR space로 바꾼후에 Reconstruction을 한다.
다른 methods들은 artifacts를 생성해내고 blurry한 것을 볼 수 있지만 RDN은 sharp edges를 생성해내고 blurry하지도 않다. 이는 "original LR image로부터 Hierarchical features를 추출해내는 것"에 기인한다고 설명하고 있다.
아래의 그림은 DN degradation model(most challenging case)에 대해서 Visually 다른 methods와 비교한 결과이다.

DN degradation model의 경우 noise때문에 왜곡되고 detail한 정보들을 잃은 상태로 network의 input으로 들어가게 되므로 다른 Methods에서는 거의 흉물스러울정도로 복원을 못했다. 그러나 RDN은 해냈다!
그래서 결론: RDN은 BD, DN degradation에 대해서 Robust하다..
Conclusions
1. RDB내의 각 layer간의 dense connection은 local feature들을 완전히 이용할 수 있도록 한다.
2. LFF는 Wider network의 training을 안정화시키고, 이전의 RDB output과 현재 RDB내의 각 local feature들의 정보들을 보존할수 있도록 해준다.
3. LRL를 사용하여 정보와 gradient가 잘 흐를 수 있도록 하였고 GFF를 통해서 LR space에서 hierarchical feature들을 추출하였다.
4. 위 과정을 통해 local & global features를 fully 이용하였고 결과적으로 다른 methods에 비해서 성능이 제일 좋았다.
댓글
댓글 쓰기