Abstract
Image Classification 분야에서는 단순히 layer를 쌓는 Chain like 모델(AlexNet)에서 부터 ResNet, DenseNet과 같은 다중의 wiring path를 가지는 모델까지 많은 발전을 일궈왔다. 그러나, 본 논문에서는 manual하게 wiring을 설계한 모델들은 wiring space가 제한되어있다는 것에 주목했고 이에 따라 Randomly wired neural networks를 통해 더 다양한 wiring pattern을 설계할 것을 제안한다.
Randomly wired neural network는 <그림 1>과 같이 일련의 과정을 거쳐 생성된다.
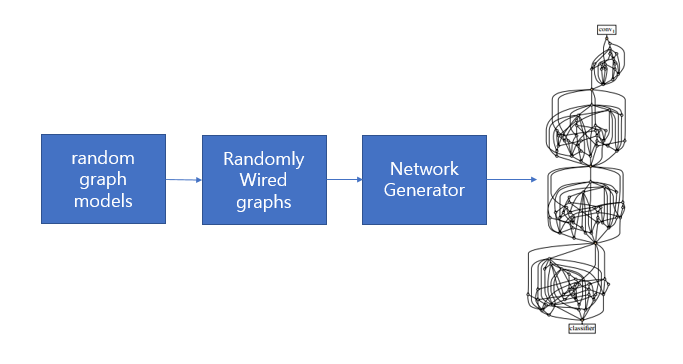
<그림 1 design of Randomly wired Neural Network>
Introduction
AlexNet과 같은 chain like wiring을 가진 model에서부터, 정교한 wiring pattern을 가진 DenseNet, ResNet 까지 발전해오면서 wiring을 어떻게 할지에 대한 연구가 진행되어왔다.
뿐만아니라, 최근까지 Neural Architecture Search(NAS)는 Network Generator를 이용하여 wiring pattern과 operation을 어떻게 구성할지에 대한 방법을 제시하였다. 그러나 Network Generator가 hand designed되어있으므로 가능한 wiring space를 제한할 수 있다는 점을 본 논문에서 주목하였다.
본 논문에서는 Random grahp model 3개(ER, BA, WS)를 이용하여 Random generator는 Randomly wired neural network를 생성하도록 하였다.
그 결과로, WS model을 이용한 network generator는 ImageNet에서 handmade network나 다른 NAS methods보다 좋은 성능 혹은 비슷한 성능을 보였다고 한다. 이 때, 하나의 generator에서 나온 서로 다른 network들의 성능은 거의 비슷했으나, 서로 다른 generator의 성능은 variance가 컸다고 한다. 이는 Network generator가 중요하다는 것을 의미한다.
또한 완전히 Random한 것은 아니라고 논문에서 주장한다. 왜냐하면, 각 random graph 모델의 wiring probability distribution이 다르므로 각 network들은 random graph의 특성을 따르게 되므로 어느정도 prior는 있다고 한다.
또한,
Feature design -> Network design -> Network generator design
방향으로 연구가 진행되어야 하지 않겠냐는 제안을 함.
Related work
Unorganized machines, Turing
- 튜링은 unrorganized machine은 초기에 random하게 construction되고 이들은 각각 특정 task를 수행할 수 있다고 주장하였다. 튜링은 신경계를 구현할 수 있는 가장 간단한 model이라고 주장했다.
F. Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain.
- "각 유기체의 신경계는 서로 각각 다르며, 태어날당시에 중요한 network들은 random하게 구성된다.
Network Generators
network generator는 아래와 같이 parameter space Θ를 넣으면 Neural Network N이 나오는 mapping 이라고 생각하면 된다.

generator는 computational graph가 어떻게 wired되는지를 결정한다(e.g. ResNet의 x + F(x)). 또한 Θ는 stage의 개수, block의 개수, depth, width, 필터 사이즈, activation type에 대한 정보를 포함할 수 있다.
이 때, N은 weight에 대한 값을 포함하지는 않고 operation type, flow of data와 같은 정보를 담고 있다고 한다.
Stochastic network Generators
위 (Θ)는 deterministic하다. 왜냐하면 Θ값이 똑같으면 항상 동일한 N을 내놓기 때문이다. 따라서 random seed값 s를 추가적인 parameter로 줘서 Θ값이 동일해도 다른 N을 내놓을 수 있도록 하였다. -> g(Θ, s)
Randomly Wired Neural Networks
기존 NAS 연구에서 Network generator는 hand designed되어있으며 human knowledge가 이미 내재되어 있다라는 것을 발견하였다. 본 연구에서는 Network generator를 어떻게 설계하느냐가 굉장히 중요하다고 생각하고 human bias가 제한된 random graph model를 통해 network generator가 network를 뱉어내도록 하는 Randomly wired neural network를 제안한다. 이는 아래와 같은 property들을 가진다.
Generating general graphs
- Graph model(ER/BA/WS)가 여러개의 node와 edge로 이루어진 graph를 뱉는다. 이 때 graph를 어떻게 neural network로 상응시킬건지는 고려하지 않는다.
- Graph를 얻은다음, mapping은 human designed 된 것(그림 2) wiring pattern에만 집중하도록 한다.

<그림 2. Node operation>
- Edge operations: directed graph이므로 data flow를 나타냄(한 노드에서 다른 노드로 tensor를 보냄)
- Node operations: 그림 2에서 보면,
1) Aggregation: 한 개의 노드는 여러개의 edge를 input 으로 받아서 weighted sum(각 weight는 learnable positive value이다.)을 해준 후,
2) Transformation: Conv를 진행한다. 이때 Conv는 ReLU-Convolution-BN을 의미한다. 이 때, Convolution은 3x3 depthwise convolution+1x1 convolution을 의미한다. 중간에 non-linearity는 없다.
3) Distribution: Conv의 output으로 나온 data를 4개로 복제하여 다른 node로 향하게 한다.
위 operation들은 각각 아주 좋은 property를 가지고 있다.
1) Additive aggregation은 output channel을 input channel과 동일하게 하여 computation cost가 증가하는 것을 막아준다. (ShuffleNet v2 에서 제시한 첫번째 guideline에 따르면, input channel과 output channel이 동일하면 Memory Access Cost를 minimize할 수 있다고 한다.)
2) 그 어떤 노드에서 나온 edge이든 wire될 수 있도록 하기 위해서 stage가 넘어가지 않는 이상 input output channel은 항상 동일하다. -> 같은 stage 내의 node끼리는 FLOPs와 parameter 수가 같다.
3) Aggregation과 Distribution에 있어서 필요한 parameter는 거의 없다(weighted sum에 필요한 w값만 존재). Node간에 edge를 연결하는데 있어서 parameter는 거의 없다는 소리이다. 반면 Parameter 개수는 거의 node 개수에 정비례한다고 생각하면 된다.
이러한 nice한 property에 따라 FLOPs와 parameter count는 network wiring에 있어서 free하다고 볼 수 있다. 실제로 서로 다른 generator에서 나온 network들은 FLOPs가 2%의 편차를 가지고 있었다고 한다. 따라서 실험을 통해 성능 차이가 난다면 그것은 model의 complexity가 아닌 wiring pattern에 기인한 것이라고 볼 수 있게 된다.
Input and output nodes
위 과정을 통해 general graph를 구성하는 edge/node operations을 확보했으나, input node와 output node가 여러개이다. 보통 일반적인 network의 input과 output은 각각 1개이므로 이에 맞추기 위하여 아래와 같은 post processing step을 진행했다고 한다.
Input node와 Output node를 둬서, input node는 original input node들에게 똑같은 data를 각각 전달해준다. output node는 original output node들으로 부터 각각 data의 data를 모아서 average하여 하나의 값으로 만든다. 즉, input node와 output node는 convolution이 없으며 단순히 data를 하나의 값으로 뭉치고 다른 노드로 전달해주는 역할을 한다. 아래의 <그림 3> 을 보면 쉽게 이해할 수 있다. 그림에서 볼 수 있듯, Output node가 input node의 역할을 할 수 도 있다.

<그림 3. Randomly wired neural network의 예>
Stages
다른 일반 Network와 마찬가지로 Input의 Resolution을 그대로 forward해주면 computation cost가 높으므로 ResNet처럼 stage를 나눠서 다음 stage로 넘어갈 때마다 input resolution을 절반 줄어들게 하고 channel수는 2배로 키우도록 했다. 이는 위 그림을 보면 잘 이해할 수 있다(가시성을 위해 stage 1에 대해서만 표기하였다).
또한, Graph model이 생성해낸 random graph는 하나의 stage에 대응한다.
구체적인 아키텍쳐는 아래 <표 1>과 같다.

<표 1. RandWire architecture>
Random Graph Models
이미 존재하는 3가지의 Graph model들을 이용하여 graph를 random하게 생성하도록하는데, 이 모델들이 undirected graph를 생성하므로 directed acyclical graph로 만들어주도록 하였다고한다.
우리의 목적은 N개의 노드를 가지는 general한 그래프를 생성시키는 것이다.
우리의 목적은 N개의 노드를 가지는 general한 그래프를 생성시키는 것이다.
Erdos-Renyi(ER): N개의 노드간에는 서로 probability P를 가지고 연결되어 있다.
아래의 그림 에서와 같이 초기에 N개의 노드를 두고 각 노드끼리 연결될 확률이 P인 그래프이다. P값이 높으면 desne한 그래프가 되고 낮으면 sparse한 그래프가 된다. 이때 P를 이 그래프의 parameter라고 볼 수 있으며 이를 ER(P)로 표기한다.
 이 그래프 모델을 통해 N개의 노드를 가지는 그래프에서 가능한 모든 wiring pattern을 나타낼 수 있게 된다.
이 그래프 모델을 통해 N개의 노드를 가지는 그래프에서 가능한 모든 wiring pattern을 나타낼 수 있게 된다.
아래의 그림 에서와 같이 초기에 N개의 노드를 두고 각 노드끼리 연결될 확률이 P인 그래프이다. P값이 높으면 desne한 그래프가 되고 낮으면 sparse한 그래프가 된다. 이때 P를 이 그래프의 parameter라고 볼 수 있으며 이를 ER(P)로 표기한다.
Barabasi-Albert(BA):
BA는 M개의 노드를 일단 만든 후, 1개의 노드를 추가시키면서 노드 개수가 총 N개가 될 때 까지 반복한다. 이 때 1개의 노드를 추가시킬 때 기존 노드에 대해서 M개의 edge를 연결 시키게 되는데 만약 기존 노드가 많은 edge를 가지고 있다면 연결될 확률이 상대적으로 높게 된다. 이는 hub역할을 하게 된다고 논문에서 설명하고 있다.
아래의 그림을 보자.
t=1에서 보면 먼저 M(1 <= M < N) 을 정한다음 M개의 node를 어떠한 edge가 없는 상태로 초기화 된다. M=3이라고 가정하겠다.
t=2에서 보면 1개의 노드가 추가되면서 M개의 edge를 기존 노드에 연결시킨다. 이 때, 기존 노드중 연결되어있는 edge개수가 많으면 많을 수록 그 노드에 연결될 확률이 높다.
t=3에서 보면 1개의 노드가 추가 되면서 M개의 edge를 기존 노드에 연결시켜야하는데, 오른쪽 맨위 노드가 연결된 edge개수가 많으므로 연결될 확률이 높게 된다.
BA 그래프 모델은 M이라는 parameter 한개를 가진다.

BA는 M개의 노드를 일단 만든 후, 1개의 노드를 추가시키면서 노드 개수가 총 N개가 될 때 까지 반복한다. 이 때 1개의 노드를 추가시킬 때 기존 노드에 대해서 M개의 edge를 연결 시키게 되는데 만약 기존 노드가 많은 edge를 가지고 있다면 연결될 확률이 상대적으로 높게 된다. 이는 hub역할을 하게 된다고 논문에서 설명하고 있다.
아래의 그림을 보자.
t=1에서 보면 먼저 M(1 <= M < N) 을 정한다음 M개의 node를 어떠한 edge가 없는 상태로 초기화 된다. M=3이라고 가정하겠다.
t=2에서 보면 1개의 노드가 추가되면서 M개의 edge를 기존 노드에 연결시킨다. 이 때, 기존 노드중 연결되어있는 edge개수가 많으면 많을 수록 그 노드에 연결될 확률이 높다.
t=3에서 보면 1개의 노드가 추가 되면서 M개의 edge를 기존 노드에 연결시켜야하는데, 오른쪽 맨위 노드가 연결된 edge개수가 많으므로 연결될 확률이 높게 된다.
BA 그래프 모델은 M이라는 parameter 한개를 가진다.
Watts-Strogatz(WS):
먼저 WS 모델은 N개의 노드를 ring 모양으로 초기화 시키고, 각 노드가 양옆으로 K/2개의 neigbor에게 연결되도록 초기화 시킨다. 그 후에 각 노드에 대해서 시계방향으로 연결된 edge(neigbor edge)를 P의 확률로 끊어버리고 중복되지 않는 edge나 자기 자신 노드를 제외한 target node중에서 uniform random하게 고른후 rewiring 해준다. 역시 말로는 어렵다. 아래 그림을 보자.
K=4라고 가정을 해보겠다. 그러면 아래의 regular graph와 같이 양옆에 K/2 = 2 개의 neighbor에게 연결되어있는 그래프가 나오게 된다. 이 때, 시계방향으로 edge를 P의 확률로 끊어서 다른 노드로 연결시키게 된다. 따라서 오른쪽의 Random graph와 같이 나오게 되는데, 자세히 보면 멀리 떨어져 있는 노드끼리도 한개 혹은 많으면 세개 노드를 거쳐서 연결되어있는 small world, facebook 친구 관계와 같은 그래프 형상을 띄는 걸 볼 수 있다.

이 그래프 모델은 K와 P의 parameter를 가진다.
먼저 WS 모델은 N개의 노드를 ring 모양으로 초기화 시키고, 각 노드가 양옆으로 K/2개의 neigbor에게 연결되도록 초기화 시킨다. 그 후에 각 노드에 대해서 시계방향으로 연결된 edge(neigbor edge)를 P의 확률로 끊어버리고 중복되지 않는 edge나 자기 자신 노드를 제외한 target node중에서 uniform random하게 고른후 rewiring 해준다. 역시 말로는 어렵다. 아래 그림을 보자.
K=4라고 가정을 해보겠다. 그러면 아래의 regular graph와 같이 양옆에 K/2 = 2 개의 neighbor에게 연결되어있는 그래프가 나오게 된다. 이 때, 시계방향으로 edge를 P의 확률로 끊어서 다른 노드로 연결시키게 된다. 따라서 오른쪽의 Random graph와 같이 나오게 되는데, 자세히 보면 멀리 떨어져 있는 노드끼리도 한개 혹은 많으면 세개 노드를 거쳐서 연결되어있는 small world, facebook 친구 관계와 같은 그래프 형상을 띄는 걸 볼 수 있다.
이 그래프 모델은 K와 P의 parameter를 가진다.
Design and Optimization
Randomly wired Neural Network는 stochastic network generator g(Θ, s)에 의해서 생성된다. 이 때, Θ에는 앞서 말한 Graph model들의 parameter (e.g. P, M, (K, P))를 포함한다. 이러한 graph parameter에 대한 optimization은 그냥 인간이 직접 한번씩 돌려주는 것이 optimization이라고 한다. 이는 다른 네트워크에서 hyper parameter를 조정하는 것과 같이 흔히 볼 수 있는 optimization이다.
또한 random seed s값을 천천히 살펴보는것 (Random search)를 통해 optimization을 진행할 수 있다. 하지만 이러한 Random search를 통해서 얻을 수 있는 accuracy variation은 근소하였다고 한다. 따라서 random search에 대해서는 수행하지 않았고, generator가 뱉어낸 network 들에 대해서 accuracy를 average한 결과값을 내놨다.
Experiments
Architecture details - <표 1> 에서 볼 수 있듯이, small computation regime와 regular computation regime architecture 각각을 고안해냈다. small 버전에서는 C=78로 맞췄고, regular 버전에서는 C=109 혹은 154로 맞췄다.
Random Seeds - 각 generator에 대해서 random seed 값을 각각 다르게 줘서 5개의 network에 대해서 실험을 진행했다. 이때, 각 generator에 대해서 어떤 random seed값을 줄 때 성능이 가장 좋게 나오는지(Random Search)는 진행하지 않았다. 5개의 network가 낸 accuracy의 mean값과 std를 사용하여 accuracy를 표기했다고 한다.
Implementation details
1. 대부분 100 epoch까지 학습을 진행
2. Half-period-cosine shaped learning rate decay 를 사용
3. 초기 learning rate : 0.1, weight decay: 5e-5, momentum: 0.9
4. label smoothing regularization with coefficient 0.1
Analysis Experiments
Random graph generators
<그림 4>에서 보면 같은 generator가 생성해낸 network들은 accuracy가 비슷하지만 다른 generator가 생성해낸 모델들 끼리는 성능차이가 많이 나는 것을 볼 수 있고, 이를 통해 random generator design의 중요성을 알 수 있다. 맨 오른쪽에 WS(K, P=0)의 경우 WS(K, P>0)의 경우보다 훨씬 성능이 낮은 것을 볼 수 있는데 이는 randomness를 적용하지 않은 것(no random wiring)이므로 성능이 낮게 나왔다고 볼 수 있다.








Random Seeds - 각 generator에 대해서 random seed 값을 각각 다르게 줘서 5개의 network에 대해서 실험을 진행했다. 이때, 각 generator에 대해서 어떤 random seed값을 줄 때 성능이 가장 좋게 나오는지(Random Search)는 진행하지 않았다. 5개의 network가 낸 accuracy의 mean값과 std를 사용하여 accuracy를 표기했다고 한다.
Implementation details
1. 대부분 100 epoch까지 학습을 진행
2. Half-period-cosine shaped learning rate decay 를 사용
3. 초기 learning rate : 0.1, weight decay: 5e-5, momentum: 0.9
4. label smoothing regularization with coefficient 0.1
Analysis Experiments
Random graph generators
<그림 4>에서 보면 같은 generator가 생성해낸 network들은 accuracy가 비슷하지만 다른 generator가 생성해낸 모델들 끼리는 성능차이가 많이 나는 것을 볼 수 있고, 이를 통해 random generator design의 중요성을 알 수 있다. 맨 오른쪽에 WS(K, P=0)의 경우 WS(K, P>0)의 경우보다 훨씬 성능이 낮은 것을 볼 수 있는데 이는 randomness를 적용하지 않은 것(no random wiring)이므로 성능이 낮게 나왔다고 볼 수 있다.
<그림 4. Small regime에 대한 각 graph model이 낸 accuracy>
<그림 5.small regime에서 각 graph model이 만들어낸 graph 들>
Graph damage
어떤 randomly wired network instance에 대해서 training을 마친 후 하나의 노드 혹은 엣지를 제거해보는 ablation study를 진행하였다.
<그림 6>에서 위쪽 그림을 보면 output degree of removed node는 제거될 하나의 노드가 얼마나 많은 노드에게 edge를 전달하고 있었느냐 를 나타내는데, 이 노드가 제거되었을 때 여러 네트워크에 대해서 accuracy drop percent를 평균값(주황점), 중앙값(회색 선), 사분범위(주황색 박스)로 나타냈고 이로인해 영향을 받는 노드의 개수를 파란색 점으로 표현하였다.
<그림 6. graph damage ablation study>
위쪽(top)에서 보면, 각 그래프마다 얼마나 영향 받는지는 각각 다르다. 가장 영향을 많이 받는 것 같은 WS 모델에서 보면 많은 노드에 연결되어서 data를 전달해주었던 역할을 했던 노드가 없어지면, accuracy drop이 심한걸 볼 수 있고 제거된 노드를 hub 라고 칭한다.
아래(bottom)에서 보면, 제거될 엣지 말고도 다른 엣지가 많은 경우에는 accuracy drop이 거의 없었지만 나말고 다른 엣지가 거의 없는 경우에는 accuracy drop이 높은것을 볼 수 있다.
Node operations
baseline model에서는 3x3 separable convolution을 사용하였고, 모든 노드에 대해서 이 대신에 3x3 일반 convolution,3x3 maxpooling/average pooling - 1x1 convolution으로 대체해 보았다.
<그림 7. node operation study>
그림 7에서 보면, 각 점은 5개의 서로다른 network에 대한 accuracy 평균값을 의미하는데 <그림 4>에서 의 네트워크들에 대해서 실험한 결과 이다. 3x3 separable conv 가 나머지 3보다 훨씬 좋은 것을 볼 수 있다. 또한 어떠한 operation을 쓰더라도 수렴을 했다는 점이 인상적이고, 3x3 pooling의 성능이 3x3 일반 conv와 비슷한점이 인상적이다.
즉, operation도 물론 중요하지만, wiring의 효과도 이것과 더불어 중요하다는 사실을 알 수 있다.
<그림 8. small computation regime에 대해서 다른 네트워크와 비교>
실험 결과에서 보면 Amoeba-C빼고는 다른 lightweight CNN architecture와 비교했을 때 상대적으로 적은 parameter수와 flops를 가지고 좋은 성능을 낸 것을 볼 수 있다.
<그림 9. regular computation regime에 대해서 다른 네트워크와 비교>
ResNet-50/101과 같은 heavy한 network와도 flops를 비슷하게 맞춰서 실험을 해본 결과가 위 그림이다. 이 때, regularization을 위해서 input degree가 1보다 큰 node의 엣지중 하나를 0.1의 확률로 제거하였다. weight decay는 1e-5, dropout는 0.2를 사용하였다. 비록 parameter 개수는 조금 더 많기는 하지만 ResNet50 보다 1.9% 높았고 ResNet101보다 0.6% 높았다.
<그림 10. Large computation regime에 대해서 다른 네트워크와 비교>
NAS기반의 heavy하고 정확도가 매우 높은 network하고 비교했을 때, FLOPs는 2/3정도만 사용하면서 parameters도 3/4정도만 사용하면서 0.7%~1.3%정도의 드랍을 보였다고 한다.
Object detection 관련해서도 backbone network로 Randwire-WS를 썼을 때 ResNet101과 같은 모델들보다 성능이 좋게 나왔다. 이는 randomwire-WS에서 학습된 feature들이 transfer가 잘 될 수 있다는 사실을 보여준다.
Conclusion
1. 3개의 서로 다른 graph model이 뱉어낸 graph를 가지고 randomly wired neural network를 생성해내도록 함.
2. 다른 hand designed model들과 비슷하거나 더 좋은 성능을 보였다.
3. 더 좋은 network generator를 기대해보겠다.
댓글
댓글 쓰기