저자: Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang
Motivation:
기존의 Single Image를 Super - Resolution하는 방식은 example-based이였다. 이는 이미지 내부의 유사성을 띄는 부분을 이용하거나 low resolution 이미지와 high resolution 이미지 사이의 mapping function을 학습하는 방식을 사용하였다.
본 논문에서는 low resolution 이미지와 high resolution 이미지 사이의 end-to-end mapping을 구축하는 것이 목적이다.
Architecture

{kind=link}
1. Patch extraction and representation:

Y는 single image에 대해서 bicubic interpolation을 통해 upscale한 것이다.
W1와 B1는 각각 Convolution filters와 Convolution Biases를 나타낸다.
Input Y에 대해서 즉, n1개의 f1 x f1 x c(input의 channel 수. 보통 3) filters들로 convolution하여 n1개의 feature maps를 만들어내고, 이를 relu에 넣는다.

전 단계 relu의 output feature들을 1x1 convolution해준다.
즉, n2개의 1 x 1 x n1 filter들로 convolution하여 n2개의 feature maps를 만들어낸후, 이를 relu에 넣는다.
3. Reconstruction:

Loss Function

n은 training sample image의 개수이고, Xi는 ground truth high-resolution image를 나타낸다. 즉, SRCNN을 거쳐서 최종적으로 나오게 되는 output과 ground truth high resolution image를 pixel wise하게 mean squared error를 계산하여 loss function을 정의하였다. 이에 따라 low 에서 high로 mapping해주는 function F가 학습된다. Optimize 방식은 stochastic gradient descent 를 사용하였다고 한다.
Training Implementation Details
1. f1 = 9, f3 = 5, n1 = 64, n2 = 32로 설정
2. Random Crop: ground truth image(Xi)는 training images로 부터 32 x 32 사이즈 만큼 random crop.
3. Blur: Gaussian_kernel(Xi) 를 통해 blur하게 만들었다.
4. Sub-sampling(pooling) by upscaling factor
5. bicubic interpolation upscaling by upscaling factor
6. 모든 Convolutional layers 는 padding이 없다.
7. MSE loss는 "Xi의 center crop된 결과물"과 "SRCNN의 output" 간에 적용된다.
8. 앞의 두개의 conv layers에 대해서는 learning rate 10−4 를 적용하였고, 마지막 layer에 대해서는 10−5 를 적용하였다.
Test Details
1. Test input 이미지는 어떤 이미지 사이즈든 괜찮다.
2. 모든 Convolutional layers는 zero-padding이 되어서, input과 output 의 size가 동일하도록 함.
3. Border의 영향을 줄이기 위해서, Relu전에 각 pixel은 valid input pixel의 개수로 나뉘어서 normalize된다.
Experiments
- Training Data
Training data로는 두가지를 써봤다고 한다.
1. 91 images - crop size 33, stride 14 를 사용해서 총 24,800개의 sub - images로 학습
2. 395,909 images ( ILSVRC 2013 ImageNet detection training partition) - crop size 33, stride 33 사용해서 총 5 M sub images 로 학습
Validation set으로는 Set5, Set14 사용하였다.
1. 아래의 사진을 통해 large dataset을 학습에 사용할 수록, SRCNN의 PSNR이 높아지는 것을 확인 할 수 있다.

- Model Performance and Trade-offs
Filter Number
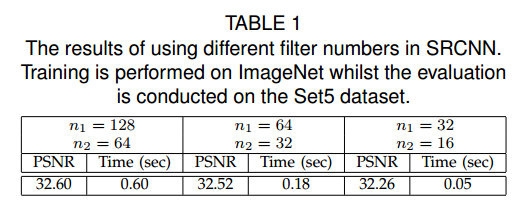
여기서 Time은 restoration 에 걸리는 총 시간을 의미한다. upscale factor는 3으로 설정했다고 한다.
filter number(width)를 늘리면, restoration의 결과 - PSNR의 값은 올라가나 speed 측면에서 많은 시간이 소요된다.
Filter Size
f1 = 9, f2 = 1, f3 = 5를 사용했을 때와 f1 = 11, f2 = 1, f3 = 7를 사용했을 때를 비교해본 결과, PSNR이 32.52 에서 32.57로 올라가는 것을 볼 수 있었다.
큰 filter size를 사용하게 되면, 풍부한 structural information들을 캐치할 수 있기 때문에 좋은 결과를 냈다고 설명하고 있다.
또한 f1,f3는 고정하고 f2를 크게해보았을때, 아래의 그림과 같이 어느정도 학습이 됬을 떄 PSNR 결과가 훨씬 좋게 나온 것을 볼 수 있다.

* (9-5-5)는 f1 = 9, f2 = 5, f3 = 5 를 의미한다.
그러나, 9-3-5와 9-5-5의 경우 performance의 차이는 미미함에도 불구하고 parameter 수는 각각 24416개, 57184개로 2배나 차이난다는 점이 trade off라고 볼 수 있다.
Number of layers
f22 = 1, n22 = 16를 가지는 non-linear mapping layer하나를 더 추가해보는 실험을 진행해보았다. 즉, 9-1-5 구조에서 9-1-1-5 로, 9-3-5 구조에서 9-3-1-5로, 9-5-5 구조에서 9-5-1-5로 network 를 조금더 deep 하게 쌓아서 실험을 했을 때, 아래의 결과를 보였다.

위 그림에서 볼 수 있듯이, deeper network들은 converge하는 속도도 상대적으로 느리고 PSNR또한 뚜렷하게 증가하는 것을 볼 수 없었다. 또한 deeper network들은 언제나 좋은 performance를 내지않았다고 한다.

(a)의 경우 9-1-1-5, n22 = 32로 설정하였을 때가 n22=16일 때보다 PSNR이 낮았고, layer를 한개 더 추가하여 9-1-1-1-5, n2=32, n23=16를 사용했을 때는 성능이 완전히 저하되는 것을 볼 수 있다.
"the deeper the better"이 어려운 이유는 SRCNN은 pooling layer나 full-connected layer가 없으므로 적절한 initialization parameters와 learning rate를 찾아 학습을 진행해야 하는데, 찾기가 힘들다. 또한 local minimum에 빠지기 쉬운 것도 작용을 한다.
따라서 three-layer network를 사용하였다고 말하고 있다.
- Comparisons to State-of-the-Arts

f1=9, f2=5, f3=5, n1=64, n2=32로 network를 설정하고, ImageNet에 대해서 학습시켜서 Set5 Dataset에 대해서 test한 것이 위의 그림이다.
학습이 진행되면서 다른 SR methods에 비해서 PSNR이 높아지는 것을 확인 할 수 있다.



여러가지 metrics 들로 State of art SR Methods를 scaling factor 2,3,4로 Set5, Set14, BSD200 Dataset에 대해서 비교한 결과 SRCNN이 모든 methods에 대해서 앞서는 것을 볼 수 있다.
IFC,NQM metric에 대해서는, SC가 Bicubic interpolation보다 더 좋은 결과를 보임에도 불구하고 더 낮은 값을 보이므로 신뢰하지 못하는 metric이라고 논문에서 설명하고 있다.
Runtime

다른 methods에 비해서 SRCNN(9-1-5)이 빠른 것을 알 수 있는데, 이는 SRCNN은 feed forward network이고, 다른 methods는 복잡한 optimization problems를 풀어야하므로 test speed에 있어서 차이가 난다고 설명하고 있다. SRCNN filter size 는 5로 늘린 결과 PSNR이 높게 나왔지만 test speed가 현저히 낮아지는 것을 볼 수 있다.
- Experiments on Color Channels

Training strategies
- Y only : single - channel(Y) network. 흑백 chanel에 대해서만 학습을 진행했으며 Cb,Cr 채널은 bicubic interpolation을 이용하여 upscale
- YCbCr: three - channel(YCbCr) network.
- Y pre-train: Y channel에 대해서만 MSE loss를 계산하여 학습하고, 그다음에 모든 channel에 대해서 MSE loss를 계산하여 fine tuning
- CbCr pre-train: Cb,Cr channel에 대해서만 MSE loss를 계산하여 학습하고, 그다음에 모든 channel에 대해서 MSE loss를 계산하여 fine tuning
- RGB: RGB channel에 대해서 학습
"YCbCr"의 경우 Bicubic보다 PSNR이 낮은 것을 볼 수 있는데, 이는 Y, Cb, Cr 채널의 각각의 다른 특징때문에 생기는 bad local miminum에 빠져서 그렇다고 설명하고 있다.
"Y Pretrain"의 경우 "CbCr pre-train"보다 더 높은 PSNR 값을 가지는 것을 볼 수 있다.
"Y pretrain"은 Y에 대해서 pretrain할 때, 많은 filter들이 활성화 되어있는 것을 볼 수 있고 따라서 fine tuning시에 성능이 좋게 나온다.
"RGB"의 경우 color image에 대해서 best 결과를 보이고 있다.
Conclusion
- Single image super-resolution deep learning approach
- Sparse-coding-based SR methods into CNN layers
- End to end mapping between low- and high resolution images with little pre/post processing
- 간단한 structure 덕분에, Image de-blurring, simultaneous SR+denoising과 같은 분야에도 적용시킬 수 있음.
Results





댓글
댓글 쓰기